Challenge 5: Robust Device Identification Under Sequential Receiver Replacement
Abstract
In long-term Internet of Things (IoT) deployments, receiver hardware may be replaced not once but multiple times over the system lifetime. Each successive replacement introduces new receiver-dependent distortions, which may compound over time and cause progressive degradation of the Radio Frequency Fingerprinting Identification (RFFI) model. The question of how to maintain reliable identification across multiple sequential hardware changes has direct implications for system robustness, resource efficiency, and long-term authentication reliability.
This challenge extends the receiver replacement problem of Challenge 4 to deployments where multiple hardware changes occur over time. Each new receiver introduces additional distortions that can accumulate and cause the identification model to drift progressively. The challenge uses the same experimental dataset as in Challenge 4, described in the Dataset section of that challenge, exploiting its multi-receiver structure to simulate a sequence of receiver replacements in a controlled setting. The goal is to develop adaptation strategies that preserve transmitter identification capability across successive receiver changes, without any labeled data from replacement receivers, by building incrementally on each previous adaptation step.
Dataset
The dataset used in this challenge is the same as in Challenge 4, described in the Dataset section of that challenge and introduced in Deliverable D5.1 [1] (Section 3.2.1). It is publicly available at: https://zenodo.org/records/14801935
The multi-receiver structure of the dataset naturally supports the simulation of sequential receiver replacements, as three receivers are available to form all possible replacement chains.
Challenge Description
No additional software is required beyond standard deep learning libraries.
This challenge considers a scenario where the receiver is replaced more than once over the system lifetime. At each replacement stage, no labeled data is available for the new receiver, and the model must be adapted using only unlabeled signals from the current receiver. The adaptation is performed sequentially: at each replacement stage, the model is adapted from the most recently adapted model, building incrementally on previous adaptation steps. The objective is to maintain reliable transmitter identification performance across all replacement stages, avoiding progressive degradation over time. This challenge follows an open benchmark format. Participants train their own models, run their own experiments, and self-report results. They are encouraged to publish their findings citing the dataset. No base model is provided; participants must train their source model from scratch.
The dataset contains three receivers, giving rise to six possible sequential replacement chains across all permutations (e.g., R1 → R2 → R3, R1 → R3 → R2, and so on). Participants are expected to evaluate all six chains and report results for each chain independently.
Data Split: The source model split defined in Challenge 4 applies here. The following additional fixed chronological splits are used for the two sequential replacement phases, applied independently per receiver, per transmitter, and per transmission distance. Data from all three transmission distances (0.5, 1, and 1.5 m) must be used in adaptation and evaluation:
- Phase 1 Adaptation: Packets 800–1399 (600 packets per transmitter per distance), unlabeled packets from the first replacement receiver.
- Phase 1 Oracle: Packets 1400–1499 (100 packets per transmitter per distance), labeled packets from the first replacement receiver. These may optionally be used strictly for adapted model selection after Phase 1. They must not be used for training or fine-tuning the model. Any use must be explicitly declared.
- Phase 1 Test: Packets 1500–1599 (100 packets per transmitter per distance), held-out packets for evaluating performance after Phase 1 adaptation. Results must be reported as secondary metrics but are not used for ranking.
- Phase 2 Adaptation: Packets 1600–2199 (600 packets per transmitter per distance), unlabeled packets from the second replacement receiver.
- Phase 2 Oracle: Packets 2200–2299 (100 packets per transmitter per distance), labeled packets from the second replacement receiver. These may optionally be used strictly for adapted model selection after Phase 2. They must not be used for training or fine-tuning the model. Any use must be explicitly declared.
- Phase 2 Test: Packets 2300–2399 (100 packets per transmitter per distance), held-out packets used to compute the primary ranking metric.
Constraint: Data from any previous receiver stage must not be reused during adaptation to a new receiver. Any use of labeled target data must be explicitly declared.
Example: A participant trains the source model using packets 0–599 from receiver R2. In Phase 1, the model is adapted to R1 or R3 using packets 800–1399 from that receiver. In Phase 2, the model is adapted to the remaining target receiver using packets 1600–2199 from that receiver. Packets 0–599 from any receiver must not be reused at any adaptation stage. Similarly, packets 800–1399 used in Phase 1 must not be reused during Phase 2 adaptation.
Input and Output
Input: Raw In-phase and Quadrature (IQ) packets from the Phase 2 Test split of each target receiver in the chain, collected at all three transmission distances (0.5, 1, and 1.5 m), with receiver identity and sequence number information provided per packet. This must be evaluated for all six receiver chains.
Output: The Average Delta-F1 score across all six sequential receiver chains at Phase 2, as defined in the Evaluation Metric section. Participants must also submit a description of their methodology, including data preprocessing steps, model architecture, training procedure, and whether Oracle splits were used for model selection.
Evaluation Metric
The primary ranking metric is the Average Delta-F1, defined as:
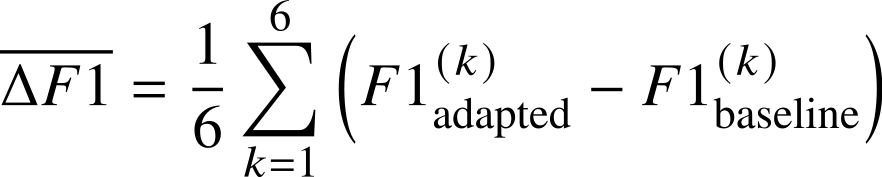
where k indexes the six sequential receiver chains, F1adapted(k) is the macro-averaged F1-score of the adapted model on the Phase 2 Test split of chain k, and F1baseline(k) is the macro-averaged F1-score of the unadapted source model on the same split. A higher ΔF1 indicates greater and more consistent performance recovery across all transfer directions. The macro-averaged F1-score is defined as:
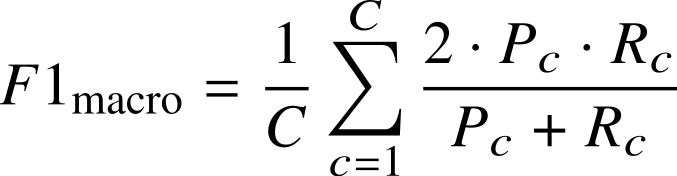
where C = 30 is the number of transmitter classes, and Pc and Rc are the precision and recall for class c, respectively. Participants must also report the per-chain Delta-F1 and absolute F1adapted scores as secondary metrics.
Bibliography
- “Deliverable D5.1: Library of known PHY attacks and PLS dataset,” Horizon Europe Project ROBUST-6G, Tech. Rep. Grant Agreement No. 101139068, 2024. PDF
To participate: submit your solution using the submission form.