Challenge 1: Contrastive Representation Learning for CSI-Based Secret Key Generation
Abstract
Secret-Key-Generation (SKG) based on channel reciprocity is a promising technique for enabling physical-layer security in Time-Division Duplex (TDD) wireless systems. However, practical SKG faces significant challenges in extracting reliable and high-entropy keys from high-dimensional, noisy, and time-varying Channel State Information (CSI), particularly in frequency-selective and multi-antenna channels. In this challenge, we focus on the feature extraction stage of the SKG pipeline and investigate mutual information–driven representation learning for CSI-based key generation. Specifically, we consider neural encoders that learn compact latent representations by maximizing the shared information between Alice’s and Bob’s reciprocal CSI observations. To address the intractability of mutual information in high-dimensional settings, we employ neural estimators based on contrastive learning objectives, particularly the InfoNCE criterion [1]. The goal is to learn representations that are robust to channel impairments and highly informative for secret key generation, enabling high key generation rate while maintaining low key disagreement.
Dataset
The dataset is available at this link: https://doi.org/10.5281/zenodo.19493713
The proposed framework is evaluated using a standardized 3GPP Clustered Delay Line (CDL) channel model based on TR 38.901 at mmWave frequency (28 GHz). The dataset captures realistic multipath propagation, spatial correlation, and temporal channel evolution under mobility.
The channel configuration is as follows: the base station is equipped with Nt = 16 antennas arranged in a uniform linear array, and the user equipment has Nr = 1 antenna. Each CSI sample consists of T = 100 OFDM symbols (time steps) and Nsub = 16 subcarriers. The CSI is provided in the frequency domain across all subcarriers, and time evolution is modeled through temporally correlated fading. The system operates in TDD mode, enabling reciprocal channel observations at Alice and Bob.
The CSI is provided as complex-valued tensors:
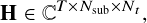
which can be equivalently represented as real-valued tensors of size T × Nsub × Nt × 2 corresponding to real and imaginary components. The dataset includes multiple propagation scenarios (CDL-A to CDL-E), different mobility regimes (e.g., 3 km/h, 30 km/h, 120 km/h).
Challenge Description
The objective of this challenge is to develop contrastive, mutual information–driven representation learning methods for CSI-based SKG in TDD systems. Participants are expected to design neural models that exploit channel reciprocity by maximizing the shared information between Alice’s and Bob’s CSI using contrastive objectives such as InfoNCE.
The learned representations should be robust to channel noise, mobility, and hardware impairments, while preserving sufficient shared information to enable reliable secret key generation. Contrastive learning methods based on the InfoNCE objective [1] provide a tractable way to approximate mutual information in high-dimensional settings. The use of standardized 3GPP CDL channel models [2] ensures realistic and reproducible evaluation conditions.
Input and Output
The input to the participant’s model consists of CSI observations from Alice and Bob, denoted as H(A) and H(B), where each tensor has dimensions H ∈ CT×Nsub×Nt (or equivalently T × Nsub × Nt × 2 in real-valued form).
The observed CSI at Alice and Bob is modeled as:

where H denotes the underlying reciprocal channel, and N(A) and N(B) are independent additive white Gaussian noise tensors. This models the practical scenario where Alice and Bob observe the same underlying channel but with independent noise realizations due to receiver noise and hardware impairments.
The output of the model must be binary key sequences for both Alice and Bob:
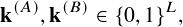
obtained from their respective CSI observations. Participants must submit a trained neural model together with inference code that maps CSI samples to quantized bit sequences. All submissions must be compatible with the provided evaluation pipeline.
Evaluation Metric
Submissions will be evaluated using the following metrics. The Key Generation Rate (KGR) is defined as:
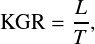
where L is the total number of generated key bits and T is the number of channel uses. The Key Disagreement Rate (KDR) is defined as:
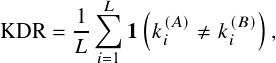
where ki(A) and ki(B) denote the i-th key bit generated at Alice and Bob, respectively, and 1(·) is the indicator function. The Normalized Mean Squared Error (NMSE) is defined as:
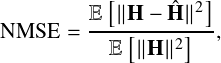
where 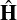 denotes the reconstructed channel obtained from the learned representation.
denotes the reconstructed channel obtained from the learned representation.
The final ranking is based on performance at a reference operating point corresponding to SNR = 15 dB with 5-bit quantization. Submissions must satisfy KDR < 5 × 10−2 and NMSE < −25 dB. Among all valid submissions, methods are ranked according to their achieved KGR, where higher values indicate better performance. In case of similar KGR, preference will be given to methods with lower computational complexity (inference time and model size) and better generalization to unseen environments.
Bibliography
- A. van den Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” 2019. https://arxiv.org/abs/1807.03748
- “Study on channel model for frequencies from 0.5 to 100 GHz,” 3GPP, Tech. Rep. TR 38.901, Mar. 2022. https://www.3gpp.org/ftp/Specs/archive/38series/38.901/
To participate: submit your solution using the submission form.